
Sector Deep Dive #8: POST-TRAINING INFRA
Companies that are building infra products for all the post-training needs

1. What exactly is “post-training infra”?
Post-training infra is the tooling layer that helps teams improve model/agent behavior after a foundation model exists. And it’s done using a mix of: supervised fine-tuning (SFT), preference tuning / RLHF-style methods, prompt/tool changes, guardrails, eval suites, and continuous monitoring in production.
As LLMs move into business-critical workflows, the bottleneck is no longer “can we run a model?” but “can we keep it correct, safe, and cost-bounded as the world changes?”. This requires an iterative loop as opposed to a one-off training job.
A useful mental model: pretraining gives you general capabilities whereas post-training infra turns those capabilities into reliable, auditable, domain-specific behavior.
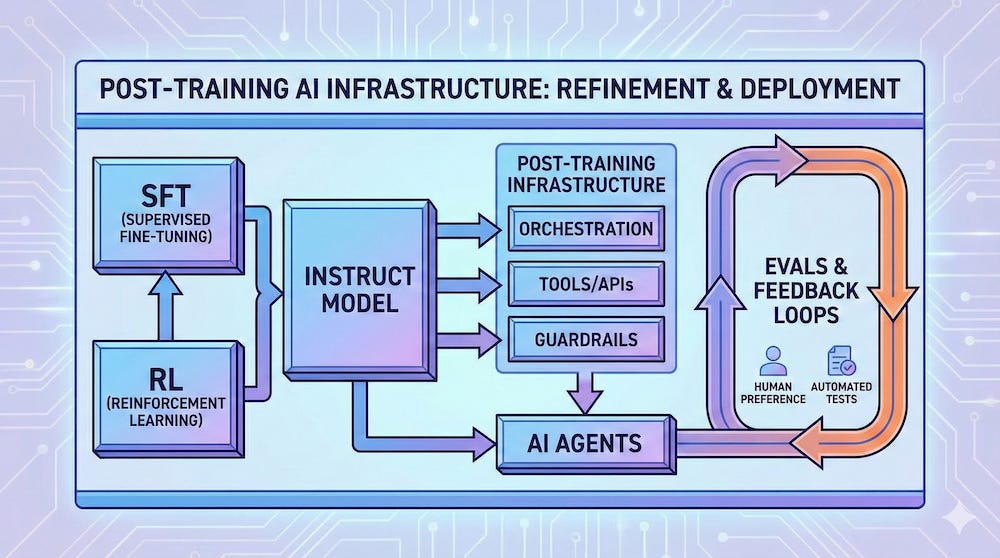
2. The post-training loop: the actual workflow enterprises are building
Across most teams, the loop looks like:
Instrument: capture prompts, tool calls, retrieval context, outputs, latency/cost, and user feedback.
Evaluate: run offline test suites + online canaries, measure task success (not just BLEU-like metrics).
Diagnose: identify failure modes e.g. hallucinations, refusal errors, prompt injection, tool misuse, drift.
Patch quickly: prompt changes, tool routing, guardrails/validators, retrieval fixes.
Escalate selectively: when patches aren’t enough, do targeted fine-tuning / preference tuning on high-value tasks.
Deploy + monitor: watch regressions, cost blowups, safety issues, repeat.
Why infra matters: each stage creates data and decision points that need to be versioned, reproducible, and connected. There is a growing trend toward “unified stacks” rather than disconnected tools e.g. TensorZero pitching gateway + observability + eval + optimization in one.
3. Demand drivers over the next 24 months
Three forces look durable through 2026:
i) Enterprise adoption is rising faster than “enterprise hardening”
A large percentage of orgs are regularly using LLMs in at least one business function. But reliability poses a big challenge. This gap (“we deployed something” vs “it’s reliable and governed”) is exactly where post-training infra sells.
ii) The world is moving to task-specific models, which increases tuning + evaluation needs
Gartner predicts that by 2027, more than 50% of AI models enterprises use will be industry/function-specific. Domain specificity means you need to make it happen through data pipelines, eval harnesses, and fine-tuning.
iii) Governance is becoming non-optional
There’s an increasing demand for monitoring, eval evidence, audit trails, and policy enforcement. Classic infra value props.
4. Subsector map: where startups cluster and who’s pulling ahead
There are six clusters with heavy convergence between them:
i) Agent/app orchestration frameworks (the “runtime” layer)
LangChain is the canonical open-source entry point. They recently raised $125M at a $1.25B valuation.
LlamaIndex positions around “knowledge agents” and enterprise data interfaces.
These frameworks become post-training companies when they add: tracing, eval harnesses, prompt/versioning, and feedback loops.
ii) Evals + testing (the “unit tests” for AI behavior)
Braintrust explicitly focuses on evals and “AI software engineering”. It announced a $36M Series A in Oct 2024.
iii) Observability + monitoring (production truth, regressions, drift)
Arize is a leading independent vendor. They announced a $70M Series C on 2025-02-20 focused on evaluation and observability for LLMs/agents.
Datadog launching LLM Observability is important because it signals bundling pressure from “classic observability” into AI stacks.
iv) Guardrails + policy enforcement (safety + reliability controls)
Guardrails AI raised a $7.5M seed and built a hub/wrapper approach.
v) Fine-tuning + preference optimization tooling (make models yours)
Lamini raised $25M for an enterprise AI platform
vi) Closed-loop optimization stacks (unifying gateway + eval + optimization)
TensorZero announced a $7.3M seed to build an open-source stack unifying gateway/observability/optimization/evals.
This is a strong signal of where the market is going: fewer dashboards, more continuous improvement pipelines.
5. Early-stage venture opportunity: where the market is still “unsolved”
The best pockets are areas where the stack is still missing a reliable primitive. Here are 4 areas where it might work:
Outcome-based evaluation (beyond LLM-as-judge)
Enterprises care about “did the agent complete the workflow correctly?” as opposed to “did it look fluent?”. But the big challenge is instrumenting ground truth from business systems (CRM, ticketing, payments) and then turning it into automated evals. Startups that own this interface can become system-of-record for AI quality.
Continuous learning for agents (safe retraining loops)
A lot of teams want self-improving agents, but they don’t trust the loop. The winning wedge is: gated data collection + audit trails + rollbacks + sandboxed deployments. This could be the next evolution after basic orchestration.
Governance + compliance automation as product
There are rules in place to push companies to document risk controls, testing, and monitoring. The infra opportunity is software that continuously produces compliance evidence (test coverage, incident trails, red-team results) as a byproduct of normal operation.
Data flywheels for post-training (high-quality feedback at scale)
Post-training quality is gated by data. Partnerships like Anthropic’s use of Surge AI’s RLHF platform illustrate the demand for scalable human feedback + QC systems. Startups that productize “feedback ops” (tools, QC, workforce routing, privacy) can be critical picks-and-shovels.
6. Business models and why pricing power is tricky
There is real revenue traction in agent building platforms. A simple derived check on how big a single customer can be under seat pricing:
If a company has 1,600 employees and pays $40–$50 per user per month, that’s:
Monthly: 1,600 × $40 = $64,000 on the low end and 1,600 × $50 = $80,000 on the high end
Annual: $768,000 to $960,000
This is attractive ARPA if adoption is broad and renewals hold
But pricing power faces two structural headwinds:
Bundling by incumbents (Datadog, cloud providers, model providers) squeezes standalone point tools.
Open source defaults (LangChain, Guardrails) force vendors to monetize via enterprise controls: SSO, RBAC, audit logs, data residency, eval governance, and support.
The likely “winning” monetization pattern is: open-core adoption → paid control plane + collaboration + compliance → usage-based expansion on monitoring/optimization.
7. How does it affect other infra subsectors?
Post-training infra doesn’t live in a vacuum. It reshapes the broader AI infra stack. Here are the most important dependencies and second-order effects:
a) Serving + inference infra becomes more valuable when evaluation loops are tight.
If teams are constantly iterating (new prompts, new adapters, new routing), they need fast, cheap experimentation environments. That pulls demand toward inference/serving startups that support canaries, model routing, and cost observability. Correlation: more eval + experimentation → more switching between models → more value in routing + caching + cost controls.
b) Data infra and security vendors get pulled into the loop
Post-training requires logging prompts and outputs, which often contain sensitive data. That creates direct dependencies on:
data loss prevention / redaction
secure storage + retention policies
access controls and audit trails
synthetic data or privacy-preserving feedback.
Regulatory pressure amplifies this because governance becomes an operational requirement.
c) Observability incumbents will “tax” the ecosystem
Datadog’s LLM Observability is a bundling signal: classic observability vendors can package AI monitoring into existing procurement, reducing budget for startups unless they are clearly better on model-specific workflows. Risk for startups is that feature parity arrives quickly (basic tracing, prompt logs, cost dashboards). Differentiation must move up the stack with actionable evals, automated fixes, and governance automation.
d) Model providers shape the ceiling
As frontier models improve, some failure modes disappear. But enterprises still need proofs, cost controls, and domain specificity. The base model progress shifts spend from “make it work at all” to “make it work reliably and cheaply”.
e) Consolidation is real (platform gravity)
CoreWeave’s acquisition of Weights & Biases shows infra providers moving upstack to own the developer workflow end-to-end (train/tune/evaluate/deploy). This creates a dependency risk: early-stage tools that don’t become a platform primitive may be acquired, copied, or squeezed.
A practical estimate for “how much of AI infra gets affected”:
if you define AI infra startups as serving one of six layers (compute, model serving, data, orchestration/devtools, observability/safety, and security/governance), then post-training infra directly overlaps orchestration + observability/safety + governance, and partially overlaps serving + data.
That’s 3–5 of 6 layers touched. The exact “portion” depends on how you bucket companies, but the direction is clear: post-training loops become a central integration point that many infra startups either plug into or compete with.
8. What to watch through 2026
Catalysts (positive for the sector)
More agent deployments → more need for continuous improvement. A large chunk of of agentic AI projects may be canceled by end of 2027 due to costs/value/risk controls. Ironically a tailwind for post-training infra that reduces those risks.
Regulatory timelines hit operational reality. Procurement starts demanding audit evidence.
Platform consolidation continues. More “W&B-style” moves by clouds, devtool incumbents, and observability platforms.
Failure modes (what breaks the bull case)
Bundling crushes standalone tools before they reach scale (especially basic eval/monitoring features).
“Good enough” models reduce willingness to fine-tune, pushing spend to prompting + retrieval. Fine-tuning platforms must show clear ROI.
Data/legal incidents (leaks, IP disputes, privacy failures) slow deployments and raise compliance friction. This can either stall budgets or redirect them to governance-heavy vendors.
9. What’s the opportunity?
The investable center of gravity is shifting from “training pipelines” to behavior pipelines. These are systems that continuously measure, correct, and harden model/agent behavior in production. The arc is: start with developer adoption, then climb into enterprise workflows by owning the feedback loop.
For early-stage venture, the best opportunities are the primitives that remain hard even as models improve:
outcome-grounded evaluation
safe continuous learning loops
governance evidence automation
feedback/data ops at scale
cost + reliability control planes across many models
The good thing is that the question “does post-training matter?” has been answered. It matters a lot! But who captures the value? Independent startups or bundled incumbents?
The next 24 months will likely reward teams that (1) become deeply embedded in production workflows and (2) generate proprietary signals (eval outcomes, failure taxonomies, policy decisions) that compound into a defensible moat.
If you are getting value from this newsletter, consider subscribing for free and sharing it with 1 infra-curious friend: