
Sector Deep Dive #4: OPEN SOURCE INFRA
Built an agent to analyze 236 open source infra repos. Graphs, charts, and trends.

I built an agent to analyze 236 open source infra repos. I wanted to extract useful signals that indicate where the world is heading. These projects collectively concentrate around a few durable themes: data infrastructure (38%), AI tooling (30%), databases+search (21%), and smaller but high-signal pockets in observability and streaming.
The set is large and mature. Median project age is around 9 years, but still very active. 75% pushed code in the last 30 days and 81% in the last 90 days. Popularity signals are strong: the median number of stars is 12.5k. As seen from the graph below, breaking past the 20k-star barrier is difficult. And beyond 40k stars is rarefied air.
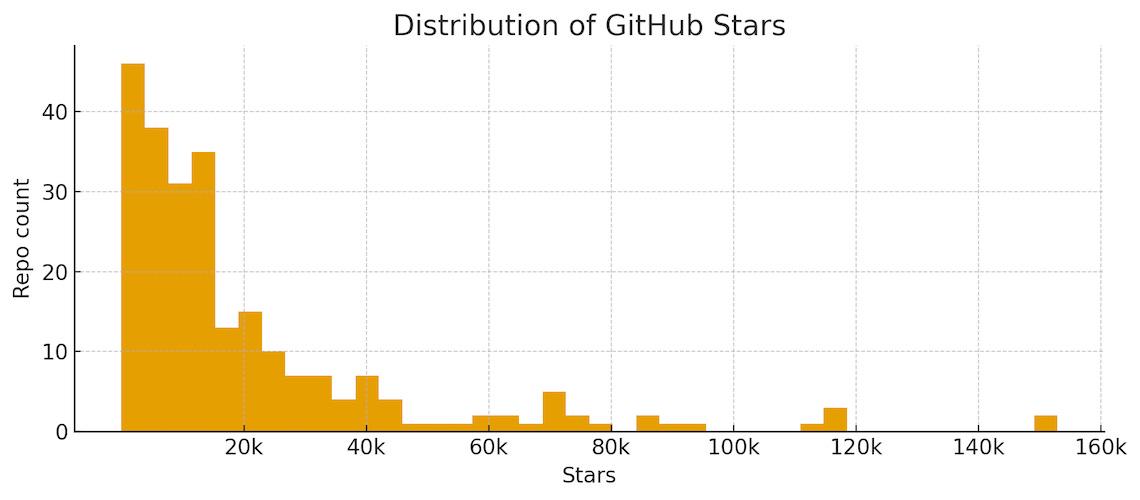
Forks and stars are highly correlated (0.81), which is consistent with communities that not only watch but also remix.
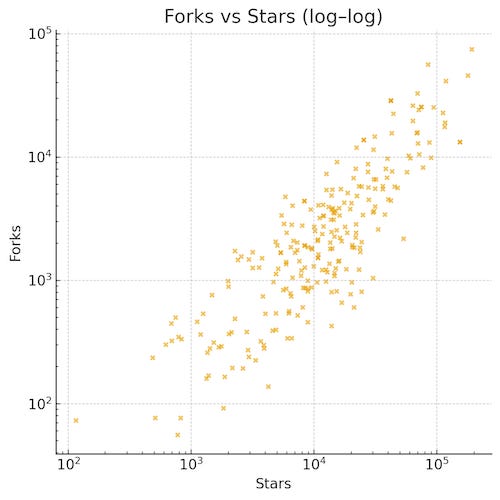
From an investor/operator lens, three patterns stand out:
Foundation-led gravity wells: Apache is the dominant owner in the dataset (22% of repos) with 85% 30-day activity. This suggests healthy stewarding and long-horizon roadmaps. Non-foundation projects skew higher on stars but slightly lower on recency of activity. Classic “breakout vs durability” trade-off.
Permissive licensing is the default: Apache 2.0 accounts for 58% of identified licenses. MIT is a distant second. For commercial builds and cloud packaging, this materially reduces legal friction and widens the potential surface for enterprise adoption and revenue capture.
Databases and data infra are “workhorse hot”: Database/search projects show 88% 30-day activity and robust median stars (13.8k). Streaming is smaller in count but similarly active (83% in 30 days). Observability is tiny by count yet shows near-universal recent activity, signaling fast iteration and a race to product-market-fit in telemetry-heavy AI / infra stacks.
Language and owner landscape
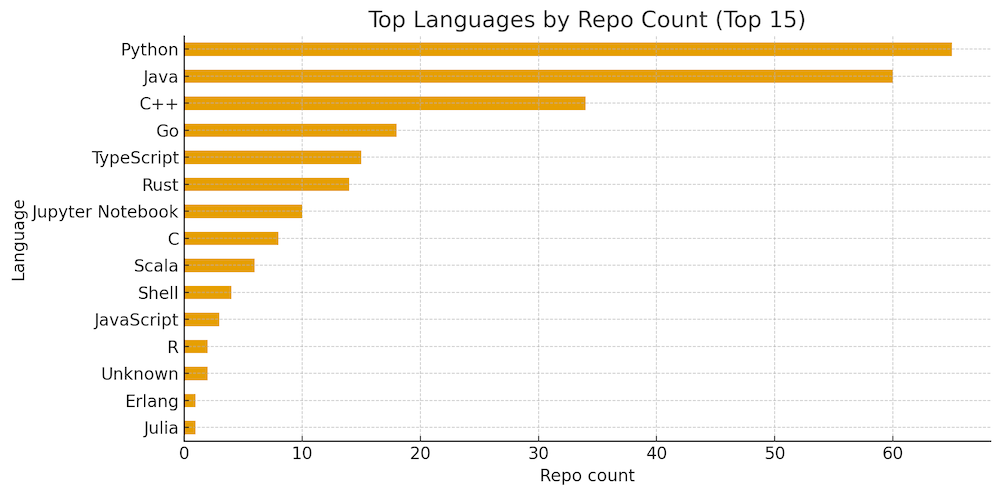
Top languages by count: Python (65), Java (60), C++ (34), Go (18), TypeScript (15). The long tail includes Rust, Scala, C, Ruby, JS, and notebooks. Median stars by language (with sample-size caution) show C++, Rust, and TypeScript/Python clustering in the mid-teens to low-20k range, while Go sits a bit lower by median in this set. Though Go projects like Kubernetes and Ollama are outliers on the high end.
Owner concentration: Apache (53 repos) is the gravitational center. Next are small clusters around facebookresearch, elastic, google, Netflix, h2oai, tidyverse, and a handful of fast-moving, company-backed AI infra owners.
Apache cohort: median stars 5.9k, median open issues 218, 85% pushed in the last 30 days. High maintenance cadence and roadmap continuity.
Non-Apache cohort: higher median stars (13.9k) and higher open issues (364), but lower 30-day activity (73%). More “breakout” but slightly more sporadic recency.
Interpretation: foundation projects optimize for stability and continuity, while non-foundation/company-backed projects skew toward velocity and viral adoption (and carry more product risk but also upside).
Licensing signals and commercialization readiness
Licenses heavily favor permissive terms:
Apache-2.0 ≈ 58% of identified licenses
MIT ≈ 8–9%, BSD variants ≈ 4–5%
Copyleft licenses are a small minority (AGPL/GPL/MPL combined ≈ low-teens count)
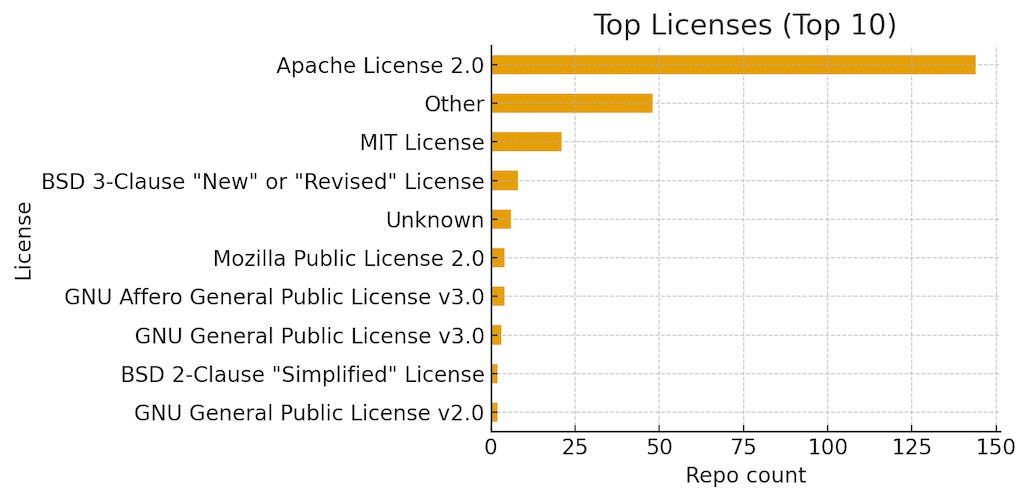
Why it matters: for infra investors and founders, permissive licenses simplify cloud packaging, commercial add-ons, and enterprise adoption. A deep Apache-2.0 bench implies fewer legal frictions for hosting and managed services. Copyleft projects can still commercialize, but with more nuanced business models (e.g. dual-license, hosted-only value capture).
Popularity and engagement dynamics
Median stars ≈ 12.5k (mean ≈ 21–22k, long-tail heavy).
Forks–stars correlation is strong (0.81) i.e. projects that attract attention also tend to accumulate derivative work/extensions, which is useful for platform bets.
Open issues correlate moderately with stars/forks (0.34): bigger communities generate more surface area for maintenance and governance, which strengthens moat if maintainers keep pace.
Age profile: median age 9 years. Cohorts are broad from 2008–2014 “classic” projects through 2019–2023 modern entrants.
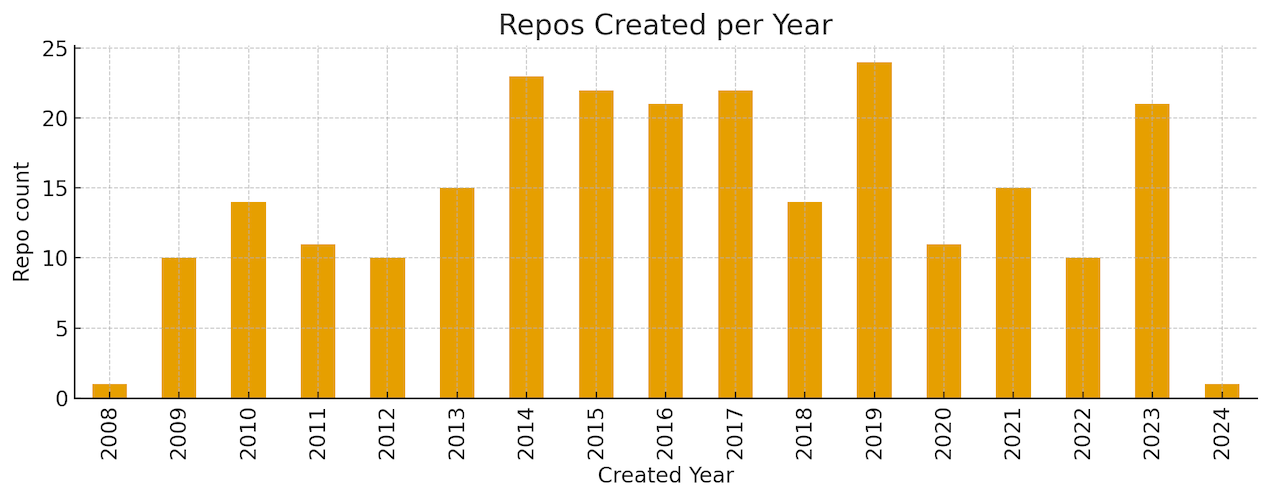
Despite age, recency is strong: 75% pushed within the last 30 days, 81% within 90 days. This is notable: a materially active base across mature infra implies ongoing fit with today’s workloads (not just legacy shelfware).
Thematic clusters
Heuristic tags show the following splits and signals:
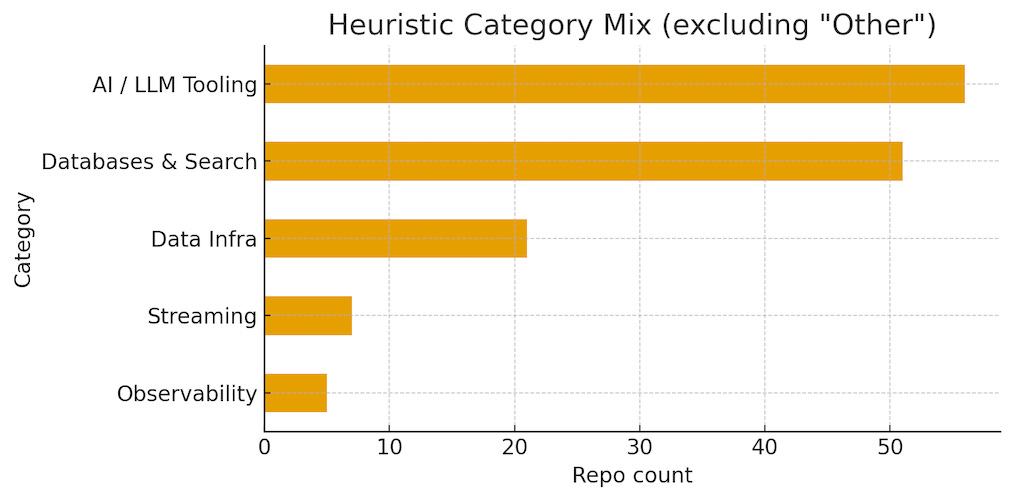
Data infra (38% of repos): ETL/ELT, lakes/warehouses, analytics engines.
Activity: 80% pushed in 30 days.
Median stars: 12.7k.
Takeaway: Large, steady engine of infra demand. Many opportunities for connective tissue (metadata, cost governance, data contracts, lineage, privacy).
AI and LLM tooling (30%): inference servers, evaluation, fine-tuning, agent frameworks.
Activity: 73% in 30 days.
Median stars: 14.9k.
Takeaway: Strong attention, slightly more volatility. Integration layers around model routing, evals, caching, safety, observability look investable if coupled with usage-linked pricing.
Databases + search (21%): transactional, analytical, vector, indexing.
Activity: 88% in 30 days (highest of the major categories).
Median stars: 13.8k.
Takeaway: Sustained build velocity and adoption. Practical moats accrue via operational excellence (HA/backup/recovery), performance on real workloads, and cloud-native operability (autoscaling, storage tiering, predictable cost).
Streaming (5%): Kafka/Pulsar-like patterns, queues, event backbones.
Activity: 83% in 30 days.
Median stars: 11.5k.
Takeaway: Smaller number but sticky demand. New growth likely at the edges (exactly-once, stateful stream processing with low-latency joins, and data contracts bridging OLTP→OLAP).
Observability/telemetry (6%): metrics, tracing, logging.
Activity: 100% in 30 days (small sample).
Median stars: 20.4k (skewed by a few big names).
Takeaway: In the AI era, infra adds non-determinism and cost volatility. And this makes telemetry essential. Expect consolidation around OTel-native pipelines + LLM-aware SLOs, test harnesses, and cost-to-quality guardrails.
Security/auth (1–2%): tiny count but fully active.
Takeaway: Greenfield for policy-as-code, Secrets/Key mgmt for multi-tenant AI, evaluation/test data governance, and RAG pipeline hardening.
What this implies for company building
Pick durability. The highest sustained activity is in databases and data infra, with observability also showing intense iteration. For a newco, tighter loops on reliability, operability, and cost predictability will outrun feature-led me-toos.
License choice is strategic. Given the dominance of Apache-2.0, deviating to copyleft will narrow the distribution surface. If your moat is cloud-operational (SLAs, SRE excellence, compliance), Apache/MIT keeps optionality high and makes enterprise POCs smoother.
Own the boring edges. The correlation between stars and forks tells you where ecosystems are fertile. But investors should underwrite the edges that cause pain in production: schema evolution, data drift, stateful upgrades, backfills, cross-region consistency, on-disk format stability, efficient vector indexes under churn, and observability that ties cost → quality for AI pipelines.
Design for platform effects. Projects that make it easier to extend (plugins, connectors, storage engines, UDFs, operators) accumulate forks and integrations. Compounding moats that are hard to unwind once embedded in workflows.
What this implies for investing
Foundation-anchored assets (Apache et al) are excellent ecosystem barometers and acquisition surfaces: look for teams that commercialize operational excellence around these standards with predictable TCO.
Company-backed AI infra with permissive licenses can scale fast but must prove defensibility beyond model access e.g. data adjacency, compliance, private fine-tunes, eval/safety/observability built in, and cost governance.
Databases/search remain investable where teams demonstrate technical advantage on real customer workloads (tail latency, compaction, tiered storage, multi-AZ replication, crash-safe durability, workload isolation) and a clean path to managed-service margins.
Telemetry/control planes for RAG/agentic systems are under-supplied. The high activity in observability hints at a forming standard: OTel first, LLM-aware signals (prompt/response lineage, caching hits, hallucination/eval scores), and unit-economics dashboards that tie GPU/egress cost to business outcomes.
Concrete opportunities to explore from the patterns
AI Data Reliability and Cost Controls: Tools that watch embedding churn, index compaction, cache efficacy, and prompt/eval drift. And automatically tune for cost-to-quality trade-offs.
Unified Schema and Lineage for Hybrid Workloads: Bridges between OLTP→stream→OLAP with contract enforcement and automated backfills.
Database-as-a-Product Ops Kits: Opinionated ops for top open source databases (bootstrap, HA, backup/restore drills, live-migrations, chaos tests, perf baselines), delivered as operator + runbooks + SRE service.
Security Hardening for RAG/Agents: Policy-as-code across retrievers, tools, model endpoints, with PII/PHI/PCI controls and reproducible evals.
Plugin fabrics where forks flourish: If a repo shows strong forks/stars, there’s room for a market of connectors/operators and “glue” that becomes the default choice.
Risks and watch-outs
Star-driven bias: Stars overweight top-of-funnel excitement. Insist on usage telemetry, self-hosted installs, and enterprise references before over-indexing.
License flips / relicensing: While rare in Apache/MIT, some projects have pivoted to source-available or dual-license. Diligence the governance and contributor agreements.
Maintainer bandwidth: Open issues scale with popularity. Ensure there’s a bus-factor plan e.g. multiple core maintainers, foundation backing, or a commercial steward.
If you like this newsletter, consider sharing it with 1 infra-curious friend: