
Programmable Reasoning: My Experiments With Qwen
Tinkering with the open source Qwen model and peeking inside

The gap between a model’s theoretical capabilities and what you can actually deploy on constrained hardware is big. And this is where the real engineering happens.
We’re familiar with reasoning, but what does it take to make it programmable? And how do we make it accessible to anyone?
To find out, I recently tinkered with the Qwen model family on a single RTX 4090 (24GB VRAM). My goal was to do everything from scratch and build two specific primitives:
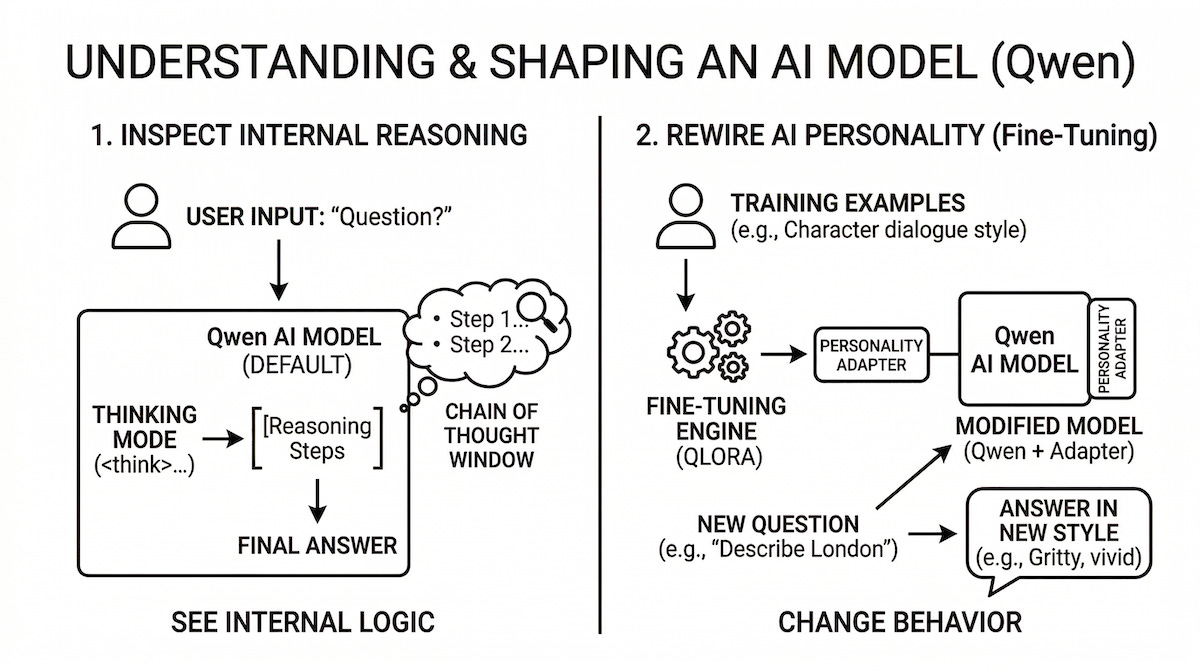
Inspecting the reasoning chain: Can we expose and parse the model’s internal “chain of thought”?
Rewiring the personality: Can we use rapid fine-tuning (flash-tuning) to fundamentally alter the model’s stylistic gravity on the fly?
I wanted to make it easily accessible via command line. Here is a breakdown of the architecture, the model quirks, and the engineering realities of building something like this.
Selecting the model
Qwen 3.5 models are highly capable, but they are multimodal under the hood. We need vLLM to serve these models. And currently, vLLM’s LoRA implementation is broken for multimodal models. This makes dynamic tuning impossible.
The Solution: I landed on Qwen3-1.7B. It’s a pure language model featuring a fascinating hybrid architecture (alternating dense and linear attention blocks), it’s fully LoRA-compatible, and crucially, it supports native “thinking mode”. And it’s small enough that you can focus on tinkering vs worrying about system/memory issues.
Objective 1: Exposing the Chain of Thought
The first goal was to peek inside the model’s reasoning process. To do this, you have to pick the right weights.
To extract the internal logic, I configured vLLM with the --reasoning-parser qwen3 flag. This cleanly intercepts the chain of thought wrapped in the <think>...</think> tokens and exposes them as a distinct reasoning field in the streaming API delta. Instead of a black box, you get a real-time window into the model’s cognitive process before it outputs the final answer.
Objective 2: Rewiring Personality via Flash-Tuning
With the reasoning engine exposed, the next goal was to see if I could rapidly bend the model’s persona to my will. I set up an end-to-end QLoRA pipeline to run a Quentin Tarantino style alignment experiment (and yes, I’m a huge fan of Quentin Tarantino).
The Setup: 5 training examples. 50 steps. Rank 8 adapter.
The Result: The loss plummeted from 4.6 to 0.12. And the model perfectly memorized the prompt formats, delivering highly stylized, rhythmic, and visceral responses for the training concepts.
However, when hit with a zero-shot, unseen prompt (”Describe London”), the LoRA broke down. The base pre-training dominated, and it reverted to a generic encyclopedia response. Five examples simply aren’t enough to generalize a stylistic syntax across the entire latent space.
The Fix: I injected a strong system prompt at inference time alongside the loaded adapter. The response to “Describe London” instantly locked in and shifted into a gritty, sensory scene: “London is a city that doesn’t lie. You walk down a street and someone walks up to you with a...”
The Lesson: A LoRA adapter successfully shifts the model’s default behavior, but the system prompt acts as the anchor. And thus locking in the style for edge cases the adapter has never explicitly seen. You need both to reliably rewire personality.
Output
I ran it from the terminal. For the chain of thought experiment, I asked about Paris but didn’t a good answer. And then I did what any good Tarantino fan would do. I summoned my inner Jules Winnfield (Pulp Fiction):
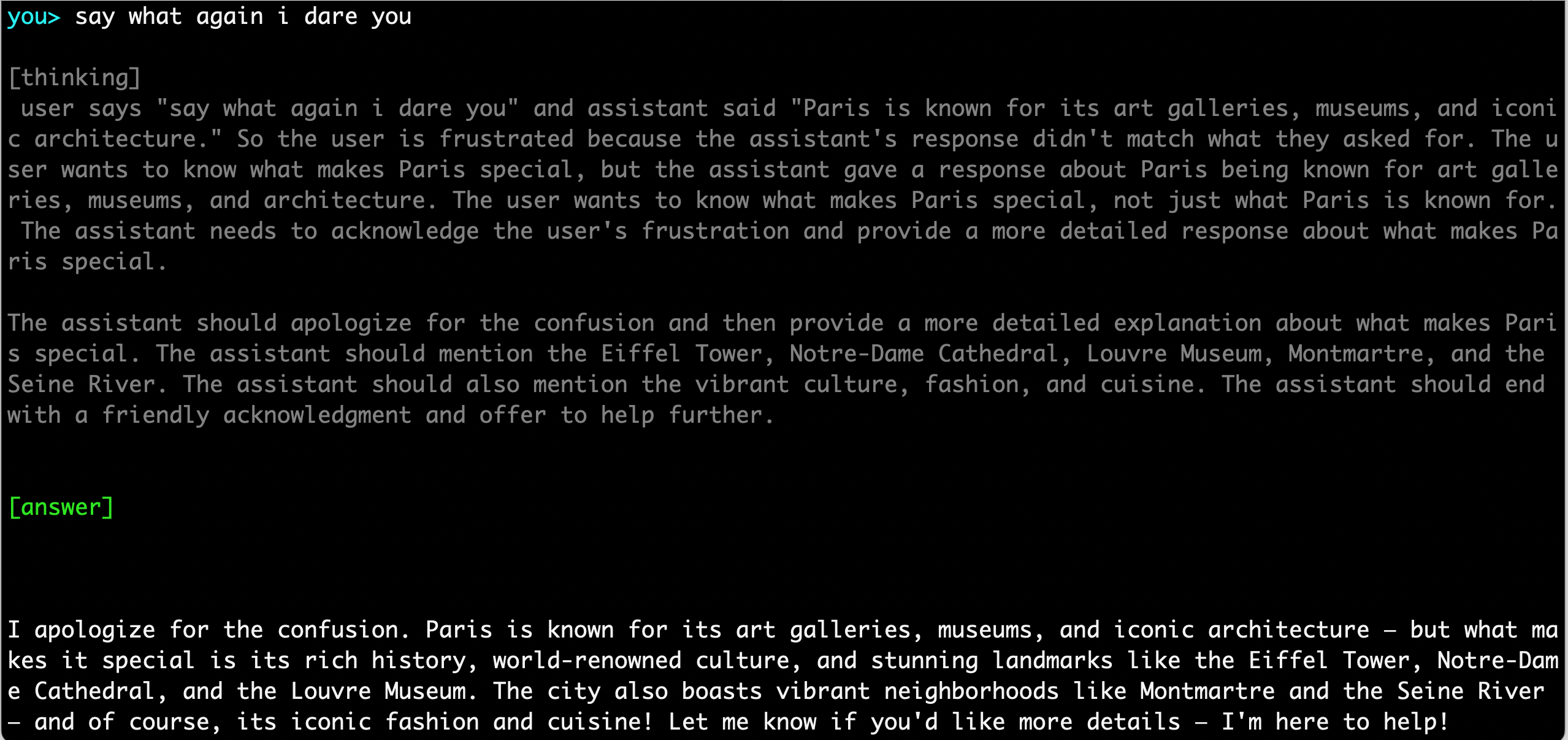
The slightly dimmed text at the top shows how the model “thinks” before answering the question. And then you can look at the bottom for the actual answer it outputted. Very interesting to see this live!
And then I wanted to rewire the model’s personality on the fly. This is what came out:
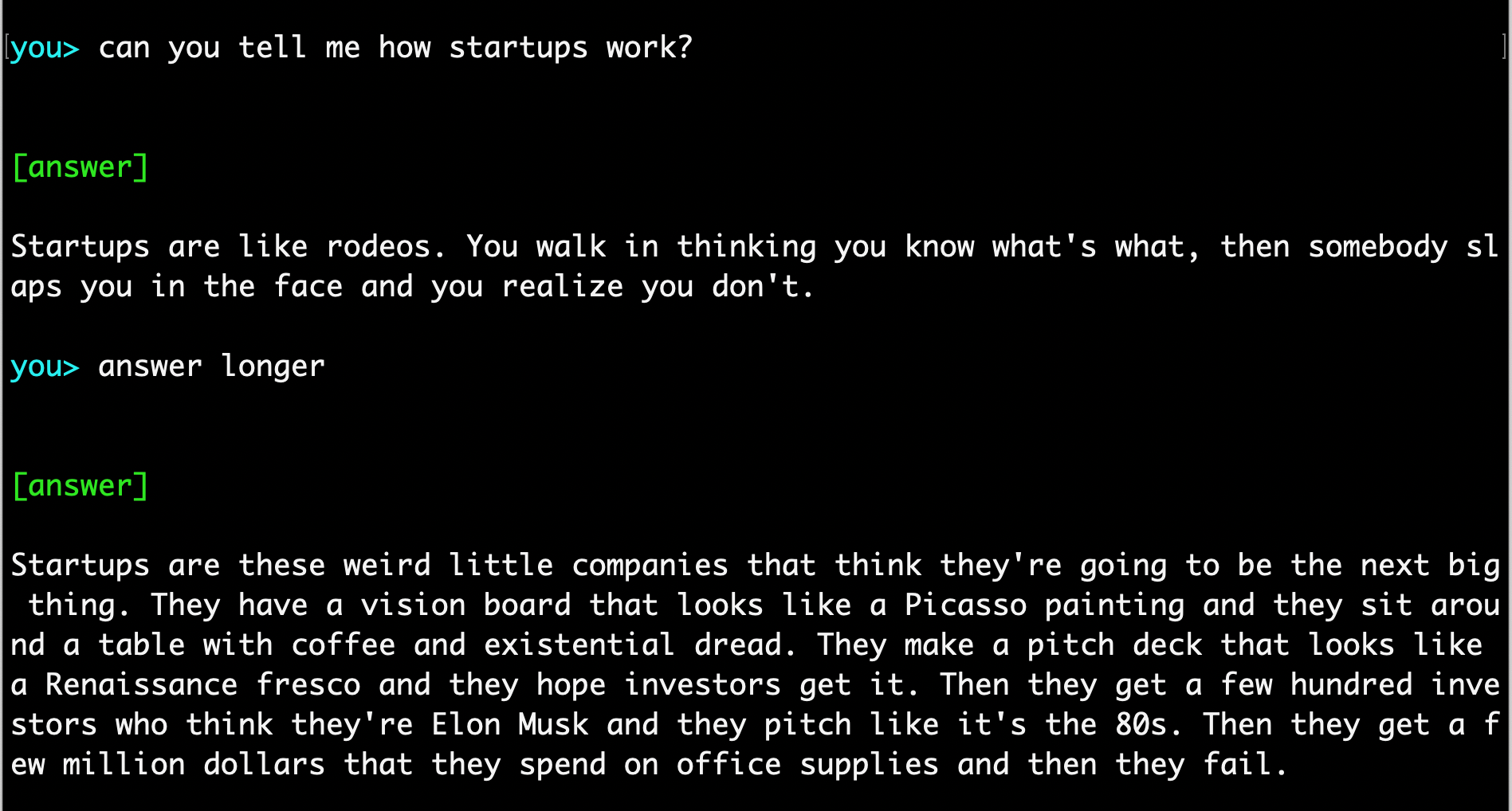
It’s fun to see this live in action.
The Infra Reality
Running both an inference server and a training pipeline on a single 24GB GPU requires strict, defensive orchestration.
A vLLM instance serving in bf16 eats ~18GB, and QLoRA needs another 12-14GB. Concurrent execution is not possible. To manage this, I built a FastAPI orchestrator that acts as a traffic controller:
VRAM Juggling: When a
POST /trainrequest hits, the orchestrator gracefully kills the vLLM subprocess, freeing the VRAM.OOM Blast Shields: The training script (
trainer.py) is never imported. It runs strictly as a subprocess. If a memory spike triggers the Linux OOM killer, it only takes down the trainer, leaving the API server alive to report the failure and restart inference.Hot-Swapping: Once training completes, the orchestrator attempts a dynamic
POST /v1/load_lora_adapterto vLLM. If that fails, it falls back to a hard restart with the new modules loaded.
Building for the Edge
Working with open-source models right now means navigating rapid library deprecations (like TRL silently renaming parameters between versions) and structural cloud limits (routing all virtual environments and pip caches to a persistent volume to avoid disk quota crashes).
But when the pipeline finally hums, it’s amazing to watch. You can watch a model “think” through a problem and then answer you in the exact voice you just injected into its weights a minute prior. Having programmable reasoning running purely on your own stack is incredibly powerful.
If you are getting value from this newsletter, consider subscribing for free and sharing it with 1 infra-curious friend: