
Mapping The Critical Token Path
Separating defensible structural moats from easily bypassed tooling

In the AI buildout, everyone wants to be infrastructure. But most “infrastructure” is just tooling.
I used to think about this mostly through inference: do the tokens pass through your node before the user gets an answer? That is still a useful test. If every live request flows through your gateway, runtime, router, policy layer, or serving stack, you are in a strong position.
But that definition is too narrow.
Because without training, there is no inference. Without post-training, the base model is not useful. Without RL environments, agents do not learn to recover from mistakes. Without memory, retrieval, caching, verification, and execution, the final answer is often too slow, too expensive, too shallow, or too unreliable.
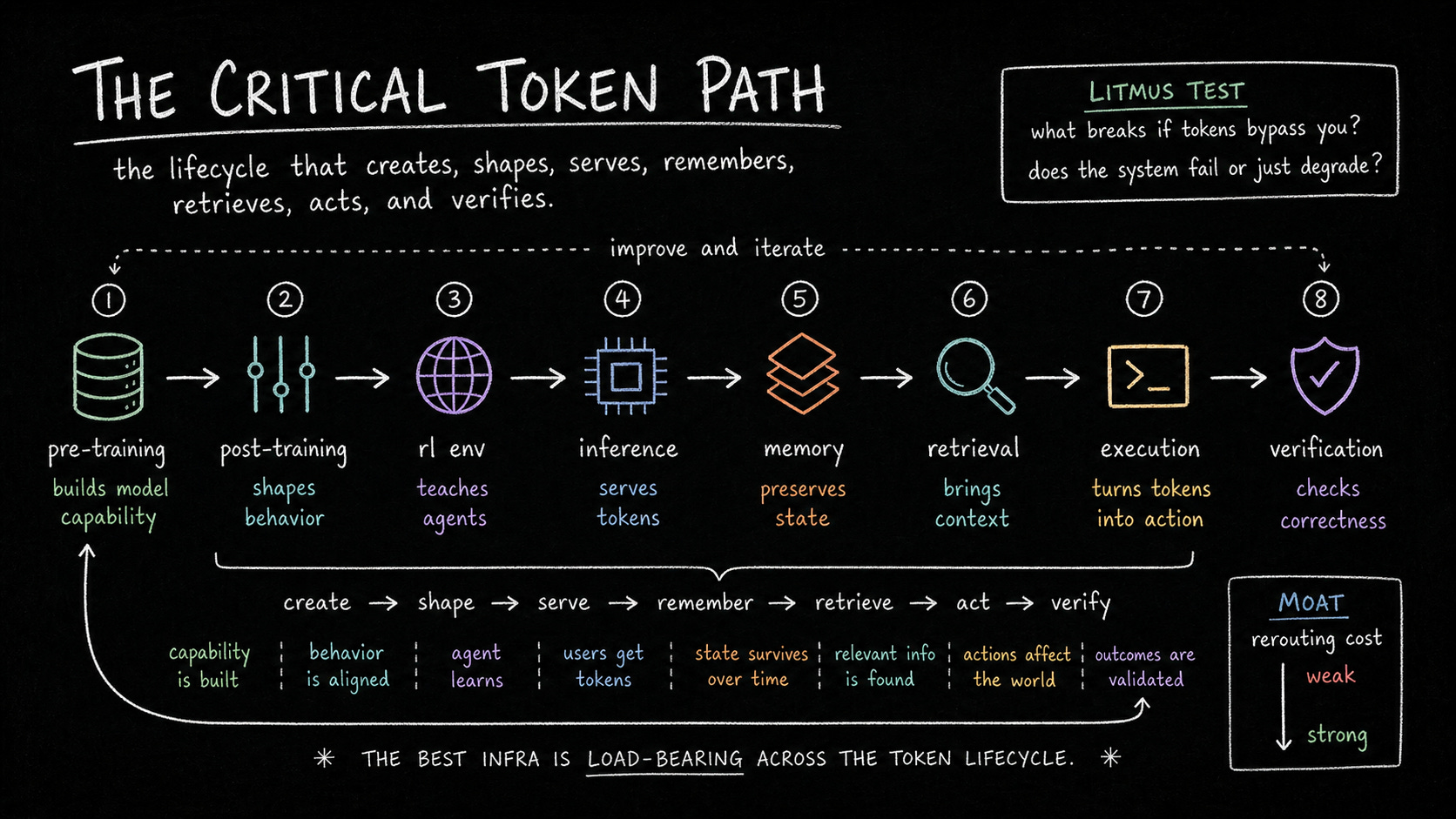
So here’s how I think about the critical token path:
The critical token path is the lifecycle that creates, shapes, serves, remembers, verifies, and acts on tokens.
The strongest AI infrastructure companies are load-bearing somewhere in that lifecycle. If the system routes around them, capability creation breaks, model quality degrades, inference cost spikes, reliability drops, or production delivery fails.
The Simple Definition
You are on the critical token path if the AI system cannot be trained, improved, served, verified, or economically operated without touching your system.
It goes beyond the live API request between the user and the model. It includes the upstream systems that create the model, the post-training systems that shape the model, the runtime systems that serve the model, and the verification systems that decide whether the model’s work can be trusted.
The question is dependency.
If removing you means the model cannot train, cannot improve, cannot run agents, cannot pass evals, cannot serve reliably, or cannot operate at acceptable cost, you are on the path.
If removing you only means a dashboard disappears, you are probably not.
Where The Tokens Actually Flow
The inference path is still the cleanest version of this framework.
Every generated token consumes compute. That makes GPUs and accelerators the obvious tollbooth: NVIDIA, AMD, TPUs, Trainium, Inferentia, and whatever specialized inference hardware comes next.
Above hardware, inference runtimes like vLLM, TensorRT-LLM, SGLang, and TGI turn raw compute into usable answers. They handle batching, memory management, KV cache optimization, quantization, scheduling, and streaming. Inference is not just “run the model”. It is the system that makes generation fast and economically viable.
Then come serving layers, gateways, and routers: Together, Fireworks, Baseten, Replicate, Modal, CoreWeave, OpenRouter. If the application calls your endpoint before it gets a model response, you are in the path.
Observability, tracing, safety, and policy become critical when they sit live inside production. A tracing proxy that sees prompts, completions, latency, cost, and errors is much closer to the token path than a dashboard after the fact. A policy gateway that every enterprise prompt and response must pass through becomes production infrastructure.
But inference is only one part of the map.
The Pre-Training Path
Before a model can generate tokens, it has to absorb tokens.
That makes pre-training infrastructure part of the critical token path. Data pipelines, data quality systems, deduplication, filtering, distributed training, GPU clusters, networking, storage, orchestration, checkpointing, and failure recovery all matter.
This is the first token factory.
The model does not emerge from the API layer. It emerges from an industrial process: collect the data, clean the data, move the data, shard the data, train across massive clusters, keep the run alive, recover from failures, save checkpoints, and push the model toward capability.
If you sit inside that process, you can be deeply load-bearing. The live user request may never touch you, but the model’s capability depends on you.
That is why training infrastructure should not be treated as separate from the token path. It is the upstream path that creates the model capable of producing tokens in the first place.
The Post-Training Path
Pre-training creates the base model. Post-training turns it into a useful product.
Instruction tuning, preference data, RLHF, RLAIF, reward models, eval harnesses, synthetic data, domain-specific task data, and alignment pipelines all live here. This is where raw capability becomes behavior.
For many frontier systems, this may be where the real product quality emerges. The base model has broad knowledge, but post-training teaches it how to answer, refuse, reason, use tools, follow instructions, and perform workflows.
This means post-training infrastructure is token-shaping infrastructure.
If a lab depends on your data, reward signal, eval harness, or feedback loop to produce better model behavior, you are on the path. The tokens may not pass through you during live inference, but the quality of those tokens was shaped by you.
That is a real dependency.
The RL Environment Path
RL environments deserve their own category.
If agents are going to become genuinely useful, they need places to practice. They need tasks, state, tools, rewards, failures, retries, and objective feedback. They need environments where they can make mistakes and learn from recovery.
That is what RL environments provide.
A good RL environment is a world. The model enters, acts, observes state, receives reward, and generates trajectories. Those trajectories become training signal. Over time, the model learns how to solve tasks, not just describe solutions.
This is especially important for coding agents, browser agents, robotics agents, data analysis agents, chip design agents, scientific agents, and enterprise workflow agents. In each case, the lab needs high-quality environments that produce verifiable feedback.
If RL environments become the way frontier labs generate scarce post-training data for agents, they become part of the critical token path.
Not because the final inference request flows through them, but because the agent’s ability to act was trained inside them.
Core dependency path
Some systems are not always in the direct token stream, but you can generate tokens without them.
KV cache is the best example. Generation is memory-bound. At scale, caching determines latency, throughput, and cost. A KV cache layer may not be the visible API endpoint. But if it lets the system serve more tokens with less hardware, it becomes a serious infrastructure layer.
Databases and retrieval systems are similar. They may not produce the final token, but they supply context. In retrieval-heavy workflows, the answer quality depends on what gets pulled into the prompt.
Agent sandboxes sit in the action path. If the model has to execute code, browse the web, manipulate files, call APIs, or operate inside a secure workspace, the sandbox becomes part of the broader production loop.
They may carry memory, context, state, tools, or execution rather than the final output token. But the token still depends on them.
The Weak Version Of AI Infra
The weak version is anything that does not create dependency.
A prompt library, generic copilot UI, lightweight dashboard, or shallow workflow wrapper can be useful. But if the model provider can absorb it, the cloud can bundle it, or the system of record can recreate it, the moat is thin.
The question is: does the system depend on it?
Can the model train without you? Can it improve without you? Can it serve without you? Can it remember without you? Can it verify without you? Can it act without you?
If the answer is yes across the board, you are not on the critical path.
You are near the action, but you are not load-bearing.
The Physical Token Path
The token path is not just software. It is also physical infrastructure.
Large-scale training and inference depend on networking, interconnect, optics, switches, memory bandwidth, storage, power, cooling, and rack-scale architecture. Before a token appears as text to the user, the computation may have crossed thousands of GPUs and moved across a dense physical fabric inside the data center.
This is why companies like Broadcom and Arista matter in the AI stack. They are in the physical path of AI computation.
The token looks like language at the surface. But underneath, it is electrons, photons, heat, and capital equipment.
As AI scales, the physical path becomes more important. More training means more clusters. More inference means more data centers. More reasoning means more compute per answer. More agents mean more long-running workloads. The software token path pulls the physical token path behind it.
The Next Token Path Is Reasoning
The old inference path was simple: prompt in, tokens out.
The new path is more complicated: prompt in, search, plan, write code, run tests, call tools, verify, retry, and then answer.
This is inference-time compute. The model thinks before responding.
As this becomes common, the critical token path expands again. If the model has to run code before answering, the execution environment matters. If it has to prove something, the theorem prover matters. If it has to query a simulator, the simulator matters. If it has to guarantee correctness, the verifier matters.
This is why verifiable reasoning environments are so interesting. They can become runtime infrastructure.
The model generates candidate reasoning. The verifier checks it. The system only returns the answer if it passes.
That is a new path: generation plus verification.
Compute Brokerage As An Economic Tollbooth
There is also an economic version of the critical path: compute brokerage.
If a platform controls GPU provisioning, scheduling, usage, reliability, and billing, it becomes a tollbooth. The token may ultimately be generated on someone else’s hardware, but the transaction flows through the broker.
RunPod is one example of this pattern.
The user does not care where the GPU physically lives. They care that the workload runs, scales, and bills correctly. If the platform aggregates supply, demand, provisioning, developer experience, reliability, and payment, it can become a durable control point.
This may not always be the deepest technical moat, but it can still be a meaningful infrastructure position.
Edge Tokens Will Have Their Own Path
Not all tokens will flow through hyperscaler clouds.
Some will be generated on phones, laptops, cars, robots, factories, medical devices, and secure enterprise environments. For these workloads, the critical path shifts from cloud serving infrastructure to local runtimes and local hardware.
This is where llama.cpp, MLX, and other local runtimes matter. They are the vLLM of the edge. They define how models are quantized, memory-mapped, executed, and streamed on constrained devices.
The token path will fragment. Some tokens will flow through frontier APIs. Some through enterprise gateways. Some through open model serving platforms. Some through local devices. Some through hybrid systems that decide dynamically where inference should run.
The question remains the same: where must the token go before the system works?
The Investor Litmus Test
When evaluating an AI infrastructure company, start with one question:
What happens if the token bypasses you?
Then expand the question across the lifecycle.
What happens if the training run bypasses you? What happens if post-training bypasses you? What happens if the RL loop bypasses you? What happens if retrieval bypasses you? What happens if the cache bypasses you? What happens if the verifier bypasses you? What happens if the serving layer bypasses you?
Does production break, quality degrade, cost spike, or reliability collapse?
Or does a dashboard disappear?
That difference is the company.
The best AI infrastructure companies become more important as models improve. More tokens mean more compute. More training means more data and clusters. More agents mean more environments and sandboxes. More reasoning means more verification. More enterprise deployment means more gateways, policy, and observability. More local inference means more edge runtimes.
They benefit from model progress. They do not fight it.
The Moat Is Rerouting Cost
The critical token path is ultimately a switching cost framework.
If replacing you requires changing a dashboard, the moat is weak. If it requires changing application code, the moat is better. If it requires changing serving infrastructure, the moat is stronger. If it requires changing training pipelines, reward loops, runtime assumptions, memory architecture, compliance policy, or data center wiring, the moat is very strong.
The best infrastructure companies are load-bearing.
They help create tokens, shape tokens, serve tokens, remember tokens, verify tokens, or act on tokens.
And rerouting around them is painful.
If you are getting value from this newsletter, consider subscribing for free and sharing it with 1 infra-curious friend: