
Four Open Source Tools I Built to Dissect AI Infra
Diving into the machinery of foundation models and AI infra

A lot of AI infra is still discussed at the level of abstractions.
People talk about agents, reasoning, open models, serving, environments, orchestration, and post-training as if these are clean categories. In practice, they are messy systems problems.
Memory breaks. Runtime assumptions leak. Models behave differently once they are actually served. Fine-tuning is easy to talk about and much harder to operationalize on commodity hardware. Agent environments sound simple until you have to make them persistent, inspectable, and usable by real workflows.
Over the last stretch, I built four open source tools to get closer to the mechanics: pforge, phabitat, pscope, and psplice.
This was not meant to be a tool-building exercise. It was research through construction. My goal was simple:
AI infra is moving too rapidly to reason about it from the outside. So to get an actual pulse, I need start touching the actual surfaces where things break.
Together, these tools form a kind of personal lab for open models and agents.
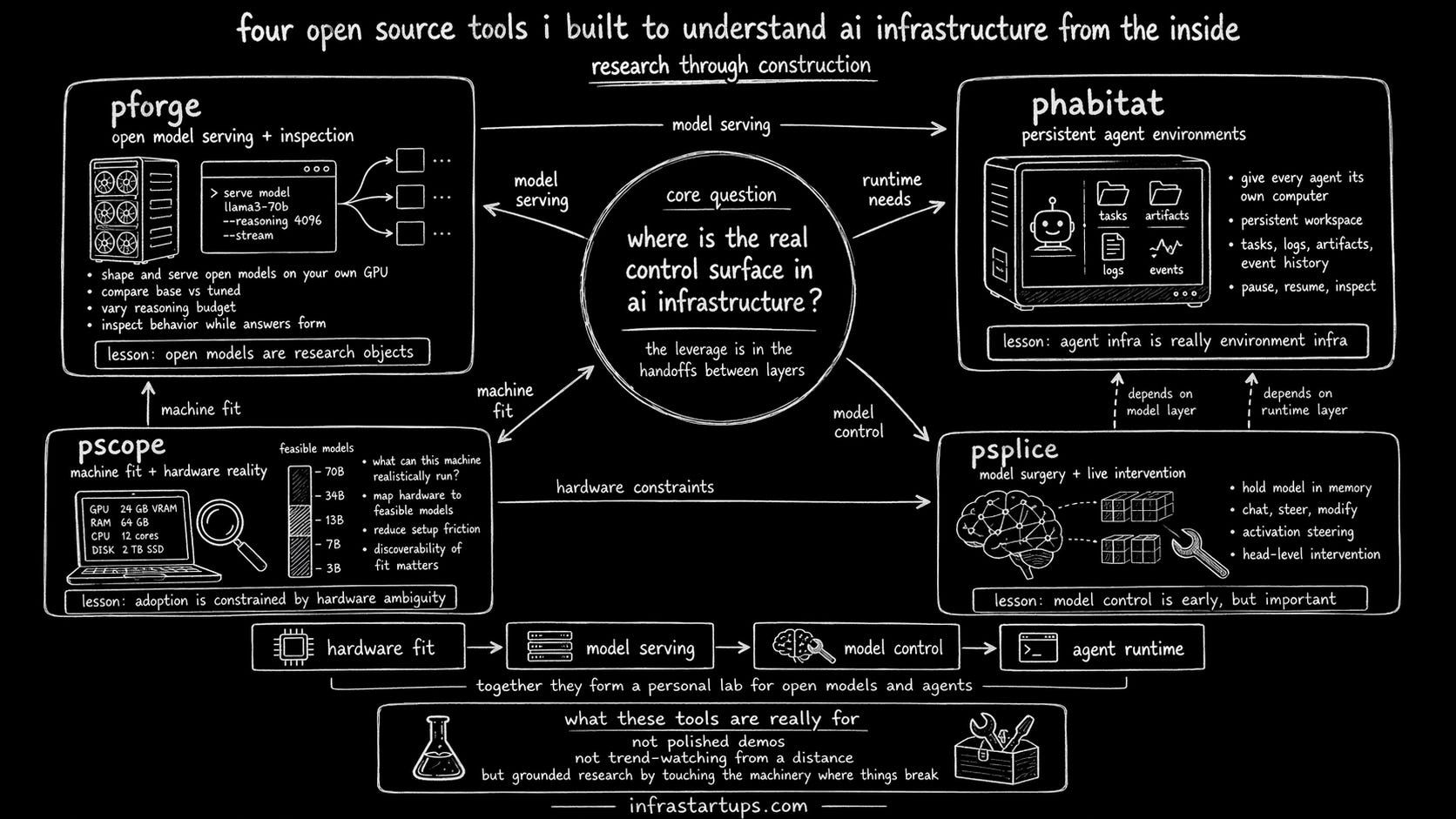
1. pforge: shaping and serving open models on your own GPU
pforge began with a basic question: what do we actually learn when we work with open models directly instead of only consuming them through an API?
Most people interact with models as black boxes. You send a prompt and get back text. But that hides the most important questions. How does latency change with model size and serving setup? What happens when you compare base and tuned variants side by side? How sensitive is behavior to reasoning budget, decoding settings, and fine-tuning? What can you inspect while the answer is forming?
pforge is my attempt to make those mechanics more visible.
It is a CLI for shaping and serving open models on a user’s own GPU machine. The emphasis is not just “run a model locally”. The emphasis is to compare, inspect, and experiment. You can chat with a model, compare outputs across variants, adjust reasoning budgets, and examine how behavior changes under different conditions.
What pforge taught me is that open models are not just cheaper substitutes for frontier APIs. They are research objects. Once you control the serving surface, you stop asking only “is this model good?” and start asking “under what constraints does this model stay useful?”
That is a much more infra-native question.
2. phabitat: giving every agent its own computer
If pforge is about the model, phabitat is about the runtime around the model.
The core idea behind phabitat is: every agent should have its own persistent workspace-scoped computer. It shouldn’t just be a stateless API call or a disposable demo session. It should be a real environment with storage, logs, artifacts, and task continuity.
This matters because a lot of agent discourse still assumes that the model is the product. I think that view is incomplete. The useful unit is often the combination of model, runtime, permissions, workspace, memory, and inspection layer.
phabitat is a CLI for spinning up these isolated environments. A user can create a habitat, assign it a plain-English task, watch it work, inspect its outputs, and return later. The agent’s workspace persists. Its artifacts persist. Its event history persists.
Building this pushed me toward a stronger view: agent infra is really environment infra.
The difficulty is not in merely calling a model repeatedly. So what’s the actual difficult part? It’s giving the system durable state, bounded permissions, legible artifacts, and enough structure that a human can trust what happened.
Once you see that clearly, the market around “agents” starts to look less like a pure model story and more like a systems story.
3. pscope: understanding what a machine can realistically run
One underrated problem in open model adoption is basic fit.
People want to run open models locally, but they often don’t know what their machine can actually support. They guess. They overestimate. Or they spend hours installing things only to hit resource ceilings later.
pscope is a small tool, but it sits on an important question: what model will run best on this machine?
It scans a system and helps map hardware reality to model feasibility. That sounds operational, but it is also research-relevant. Hardware constraints shape what developers can build, test, and learn. They determine whether open models feel accessible or frustrating. They shape which parts of the ecosystem become broadly usable.
Working on pscope reinforced a simple belief. Infra adoption is often constrained less by raw model quality and more by setup friction plus hardware ambiguity.
In other words, discoverability of fit matters. A lot.
4. psplice: model surgery, steering, and live intervention
psplice is probably the most research-heavy of the four.
The goal is to make model intervention more practical. Load a model once, hold it in memory through a daemon, and then let the user perform operations like chatting, steering, and modifying behavior without reloading everything each time.
This tool sits closer to the layer of “how can I alter model behavior directly?” rather than “how can I wrap a product around it?”
That includes things like activation steering and head-level interventions. Even implementing the ergonomics of this forces you to confront real system details: attention implementations, VRAM persistence, daemon architecture, tensor assumptions, and the gap between a neat conceptual technique and a usable tool.
psplice taught me that model control is still early. Many ideas sound elegant in papers and rough in practice. But this is exactly why building matters. It reveals which interventions are robust, which are brittle, and which might eventually matter for real workflows.
What these tools are really for
On the surface, these are four separate open source projects.
Underneath, they are all attempts to answer the same research question: where is the real control surface in AI infra?
Is it the model weights? The serving stack? The environment around the agent? The hardware fit layer? The intervention interface?
My current view is that the answer is not a single layer. The leverage comes from understanding the handoffs between layers.
That is why I built these. I want to build enough of the stack myself that my research can be grounded in contact with the machinery.
That’s the standard I want for my Infra Startups research column. Research should not just summarize what others built. It should leave evidence that you have wrestled with the systems yourself.
If you are getting value from this newsletter, consider subscribing for free and sharing it with 1 infra-curious friend: