
Agents Need Worlds: Building Verifiable Environments From Scratch
A local-first experiment in turning agent actions, failures, and recoveries into replayable training signal

If you want to train an AI agent, a prompt is not enough. A prompt gives the agent an instruction. But real work doesn’t happen inside an instruction.
Real work happens inside an environment. There is state. There are tools. There are constraints. There are consequences. You try something, observe what changed, recover from mistakes, and eventually reach a useful outcome.
I wanted to see what it takes to build an environment from scratch. And that’s the premise behind pworlds, a tool I built to explore this simple thesis.
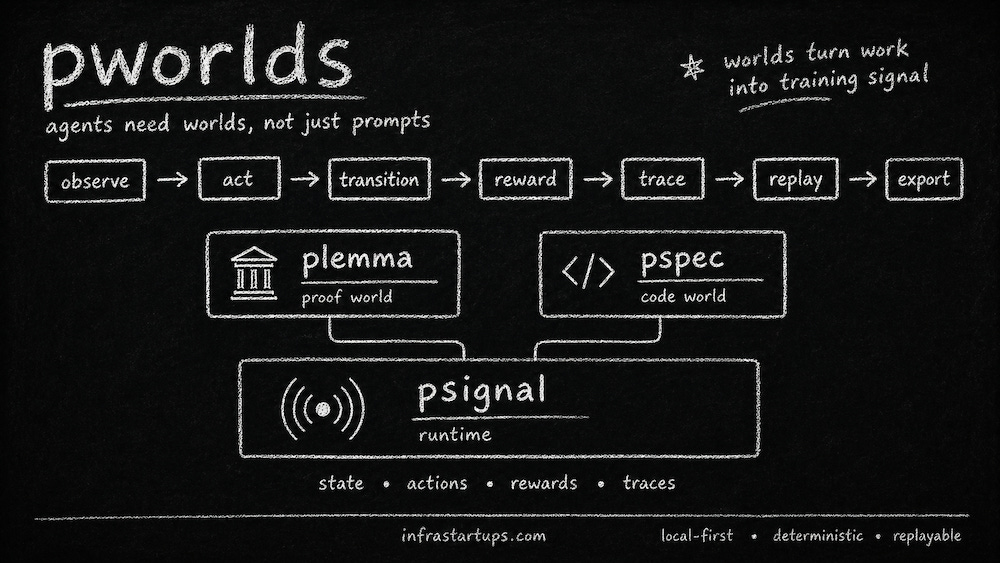
So what is pworlds? It’s a collection of verifiable task environments for agents. It is not a chatbot wrapper, a benchmark suite, or a generic RL framework. It is closer to environment engineering for agent training. The goal is to create small executable worlds where agents can act, receive objective feedback, generate traces, and export training signal.
The Problem With Final Answers
Most AI evaluation still over-focuses on final answers.
Did the model solve the problem?
Did it pass the test?
Did it produce the right output?
Those questions matter, but they miss the messy middle.
In real work, the process is often more informative than the answer. What did the agent try first? What failed? What changed? What feedback did it receive? How did it recover?
That is the kind of signal I wanted pworlds to capture.
A world is not just a question with an answer. A world has state. A world accepts actions. A world changes when those actions are taken. A world can grade whether progress was made. And if designed correctly, a world can record the full path from initial state to successful outcome.
That path is where the valuable data lives.
The Constraint: Keep It Local And Small
From the beginning, I forced the project to stay small.
The first version had to be local-only. No GPU requirement. No model training. No OpenAI integration. No Anthropic integration. No cloud services. No database. No Docker. No plugin-heavy architecture.
The abstractions had to stay clean, but small. The priority was CLI usability, tests, determinism, and extensibility.
Those constraints were not arbitrary. They prevented the project from prematurely becoming a platform.
Before building distributed infra, I wanted to prove the runtime pattern:
Can we make a task executable?
Can we expose state?
Can we accept actions?
Can we compute rewards?
Can we record traces?
Can we replay a trajectory?
Can we export the result as training signal?
That was the core question.
psignal: The Runtime Substrate
The first package I built was psignal.
psignal is the shared substrate underneath pworlds. Its job is to turn executable tasks into training signal.
The loop is straightforward:
task → observe → action → transition → reward → trace → replay → export
Instead of hiding state in a database or service, psignal makes every task a visible local artifact on disk. When a task is created, the system generates files like psignal.yaml, state.json, trace.jsonl, and a README.
The metadata lives in the YAML file. The current state lives in JSON. The trajectory is appended line by line into JSONL.
That file-backed design ended up being one of the most important decisions in the project. It made everything inspectable. You can open the folder and see what happened. It made the system debuggable, portable, git-friendly, and easy to explain.
The Smallest Possible World
The first built-in environment was intentionally tiny: a counter.
The task starts at zero. The goal is to reach five. The valid actions are +1, -1, and reset.
If the task reaches the goal, it gets a positive reward. If it takes a valid but incomplete step, it receives a small penalty. If it takes an invalid action, it receives a larger penalty.
That may sound too simple, but that was exactly why it was useful.
The counter is the smallest possible environment that still demonstrates the full runtime pattern. There is persistent state. There are explicit actions. There are valid and invalid moves. There is an objective success condition. There is a trace. There is replay. There is export.
Before proving the system could handle complex work, I wanted to prove that the loop itself was clean.
plemma: A Theorem-Proving World
Once psignal worked, the next question was whether this substrate could support something more meaningful than a toy counter.
That led to plemma, the first real world built on top of psignal.
plemma is a theorem-proving world. I chose theorem proving because it is a high-signal domain for objective agent interaction. A proof state is explicit. Actions are discrete. Some moves are valid. Some are invalid. Success is not a matter of taste. Either the proof completes or it does not.
The long-term direction is Lean-style theorem proving, but the first version deliberately avoided full Lean integration. Instead, plemma used a simulated tactic environment and failed gracefully if a real Lean toolchain was missing.
The initial theorem was simple: prove identity. The valid path was intro h, then exact h.
That was enough to make the abstraction legible.
In the counter world, actions manipulate integer state. In the theorem world, actions manipulate proof state. Same runtime pattern, different domain.
This was the first important proof point. Now pworlds went from just being a counter demo to representing symbolic work.
pspec: A Software Engineering World
But theorem proving is still niche, so I wanted a second world that would be more broadly understandable.
That became pspec, a software engineering world.
pspec is a coding-task environment. The first version used a small buggy FizzBuzz function. The task had a source file, tests, metadata, state, trace, and reward function.
The workflow was simple:
Inspect the code.
Edit the file.
Run the tests.
Receive feedback.
Record the step.
Try again.
This is much closer to how real software work happens. You do not jump from broken code to final patch. You inspect, edit, run tests, fail, edit again, and eventually pass.
The intermediate attempts are not noise. They are the process. And the process is the training signal.
The Important Distinction In pspec
Building pspec revealed an important distinction.
In the counter world, the action is typed directly into the CLI. You say +1, and the environment updates the count.
In the theorem world, the action is also typed directly into the CLI. You say intro h, and the environment updates the proof state.
But in the coding world, the meaningful action is not the CLI command. The meaningful action is the file edit.
The CLI action is only run-tests.
That distinction matters because pspec is not a patch-application DSL. It is a local repair environment. A human or agent edits files in the workspace. Then pspec evaluates the current code state by running tests and recording the result.
That model feels much closer to actual agent work.
The Trajectory Is The Data
pspec records more than just whether the tests pass.
It can record the current source snapshot, source hash, test output, reward, completion status, and the diff between evaluated steps.
That diff is especially important. It turns the trajectory from a sequence of states into a sequence of state transitions.
So the output is not merely: “Here is the final fixed file”
The output is: “Here is the buggy starting point. Here is the first attempted change. Here is what failed. Here is the next diff. Here is the test feedback. Here is the moment the task became correct.”
That is a much richer object for agent training. A final answer tells you what worked. A trajectory tells you how the work got done.
From Local Debugging To Training Artifacts
After the initial pspec version, I added support for custom tasks.
You can create a task from a real Python source file and a test file or test directory. pspec copies the source and tests into a task folder, stores a hidden reset template, tracks evaluated edits, captures diffs, and can package the whole thing into a single training_artifact.json.
That packaging step matters operationally.
Without it, handing data to a training team means explaining which files matter, where the trace lives, how the tests relate to the source, and what the final state represents.
With packaging, the output becomes one structured artifact containing metadata, state, source files, test files, traces, and exports.
This is the bridge from local debugging to process-data generation.
What pworlds Is Not
pworlds is not a training platform.
It is not a model-serving platform. It is not a cloud orchestration system. It is not a benchmark leaderboard. It is not a full Lean integration. It is not an autonomous coding agent.
It is an early substrate for verifiable task environments.
But even in this early form, the pattern is visible. The same runtime can support integer control, theorem proving, and code repair.
Those are three very different domains, but they all fit the same loop:
observe → act → transition → reward → trace → replay → export
That is the core abstraction.
The Bigger Point
A lot of the AI world still thinks in prompts.
Better prompts. Longer prompts. More structured prompts. Prompt libraries. Prompt workflows.
Those things are useful, but they are not enough for agents that need to do real work. Real agents need environments.
A coding agent needs broken repos, tests, diffs, intermediate failures, and repair trajectories.
A theorem-proving agent needs proof states, tactic attempts, invalid moves, and verified completions.
A data-center operations agent needs simulated incidents, control actions, safety constraints, and recovery paths.
A chip-design agent needs toolchains, timing reports, constraints, compiler feedback, and objective pass/fail signals.
The domain changes, but the pattern stays the same.
Build the world. Expose the state. Let the agent act. Grade the outcome. Record the trace. Replay the trajectory. Export the signal.
Why This Matters
The frontier labs already have a lot of text.
What they increasingly need is high-quality process data from environments where outcomes are verifiable.
Not just answers, but attempts.
Not just scores, but trajectories.
Not just final patches, but the path from broken to working.
If we can turn high-value work into executable environments, then every attempt becomes data. Every failure becomes signal. Every recovery becomes part of the training distribution.
If you’ve been building or investing in this direction, I’d love to chat with you.
If you are getting value from this newsletter, consider subscribing for free and sharing it with 1 infra-curious friend: